AI Pulse: Brazil Gets Bold with Meta, Interpol’s Red Flag & more


AI is advancing at such a fast pace that regulators, governments, and content creators are having a hard time keeping up. This edition of AI Pulse takes a deep dive into the topic of AI regulation, from Brazil’s Meta challenge and creators’ copyright defenses to recent law enforcement warnings and a contemplation on what will happen once agentic AI starts to ‘think’ for itself.
AI regulation: Who’s driving the bus?
Almost as soon as generative AI hit the scene, critics started sounding alarms about AI companies’ rampant consumption of data for training their models. Arguments continue to rage over whose data is it, who has the right to use it—and where and how.
The high speed and low transparency of AI innovation have made it tough for content owners, regulators, and legislators to keep up, but that hasn’t stopped them from trying. In the last few weeks and months, authorities have put the brakes on some big players’ ambitions while vocal communities have aired their frustrations—sometimes in hard-hitting ways.
This AI Pulse looks at a few key developments in AI regulation and why guardrails are going to be more important than ever with the rise of ‘agentic’ AI.
What’s new in AI regulation
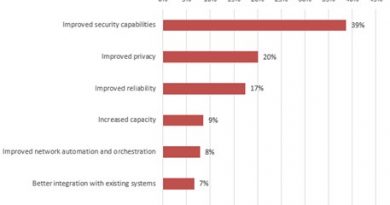
Regulators flex on the AI feeding frenzy
Brazil delivered bad news to Meta at the start of July when it halted the company’s plan to train AI models on Instagram and Facebook posts. According to the BBC, Meta aimed to scrape public posts, images, and comments for AI training. Content would have included posts by children and teens. Meta said its plan conformed to Brazilian privacy laws; the country’s data protection agency, the ANPD (Autoridade Nacional de Proteção de Dados), said otherwise.
Meta had already backed off a similar move in the EU under pressure from governments there, and more recently announced it would not be deploying its next multimodal AI model in Europe or Brazil because of a lack of clarity about regulations. (Multimodal AI models make use of the full range of media instead of just text, video, or images on their own.) Whether or not this is related to the EU’s AI Act passing in July, the act ‘going live’ means the clock is now ticking for companies to comply.
Whose data is it, anyway?
AI regulation touches on questions of copyright and data privacy that are governed by other, preexisting legal frameworks. Back in January 2024, Italy found OpenAI was likely in violation of one of those frameworks, the EU’s GDPR, in a case that’s still ongoing.
Part of the issue comes down to what constitutes ‘publicly available’ data—which AI companies and regulators tend to see very differently. As a recent Axios feature noted, ‘publicly available’ and public domain are not the same thing, and much of what AI innovators consider publicly available is obtained without explicit user or creator permission, intentionally or otherwise. When a July WIRED story suggested some companies may have violated YouTube policies by using subtitles from videos to train AI platforms, it was acknowledged this may not have been deliberate since the underlying dataset had been collected by a third party.
Read More HERE