Machine Learning Improves Prediction of Exploited Vulnerabilities
A public effort to create a way of predicting the exploitation of vulnerabilities announced a new machine learning model that improves its prediction capabilities by 82%, a significant boost, according to the team of researchers behind the project. Organizations can access the model, which will go live on Mar. 7, via an API to identify the highest scoring software flaws at any moment in time.
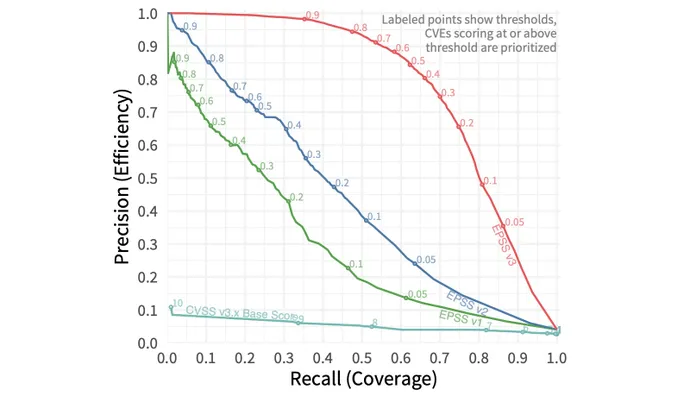
The third version of the Exploit Prediction Scoring System (EPSS) uses more than 1,400 features — such as the age of the vulnerability, whether it is remotely exploitable, and whether a specific vendor is affected — to successfully predict which software issues will be exploited in the next 30 days. Security teams that prioritize vulnerability remediation based on the scoring system could reduce their remediation workload to an eighth of the effort by using the latest version of the Common Vulnerability Scoring System (CVSS), according to a paper on EPSS version 3 published to arXiv last week.
EPSS can be used as a tool to reduce workloads on security teams, while enabling companies to remediate the vulnerabilities that represent the most risk, says Jay Jacobs, chief data scientist at Cyentia Institute and first author on the paper.
“Companies can look at the top end of the list of scores and start to work their way down — factoring in … asset importance, criticality, location, compensating controls — and remediate what they can,” he says. “If it’s really high, maybe they do want to bump it into critical — let’s fix it in the next five days.”
The EPSS is designed to address two problems that security teams face on a daily basis: keeping up with the increasing number of software vulnerabilities disclosed every year, and determining which vulnerabilities represent the most risk. In 2022, for example, more than 25,000 vulnerabilities were reported into the Common Vulnerabilities and Exposure (CVE) database maintained by MITRE, according to the National Vulnerability Database.
Work on EPSS started at Cyentia, but now a group of about 170 security practitioners has formed a Special Interest Group (SIG) as part of the Forum of Incident Response and Security Teams (FIRST) to continue to develop the model. Other research teams have developed alternative machine learning models, such as Expected Exploitability.
Previous measures of the risk represented by a particular vulnerability — typically, the Common Vulnerability Scoring System (CVSS) — do not work well, says Sasha Romanosky, a senior policy researcher at the RAND Corporation, a public-policy think tank and co-chair of the EPSS Special Interest Group.
“While CVSS is useful for capturing the impact [or] severity of a vuln, it’s not a useful measure of threat — we’ve fundamentally lacked that capability as an industry, and this is the gap that EPSS seeks to fill,” he says. “The good news is that as we integrate more exploit data from more vendors, our scores will get better and better.”
Connecting Disparate Data
The Exploit Prediction Scoring System connects a variety of data from third parties, including information from software maintainers, code from exploit databases, and exploit events submitted by security firms. By connecting all of these events through a common identifier for each vulnerability — the CVE — a machine learning model can learn the factors that could indicate whether the flaw will be exploited. For example, whether the vulnerability allows code execution, whether instructions on how to exploit the vulnerability have been published to any of three major exploit databases, and how many references are mentioned in the CVE are all factors that can be used to predict whether a vulnerability will be exploited.
The model behind the EPSS has grown more complex over time. The first iteration only had 16 variables and reduced the effort by 44%, compared to 58%, if vulnerabilities were evaluated with the Common Vulnerability Scoring System (CVSS) and considered critical (7 or higher on the 10-point scale). EPSS version 2 greatly expanded the number of variables to more than 1,100. The latest version added about 300 more.
The prediction model carries tradeoffs — for example, between how many exploitable vulnerabilities it catches and the rate of false positives — but overall is pretty efficient, says Rand’s Romanosky.
“While no solution is perfectly able to tell you which vulnerability will be exploited next, I’d like to think that EPSS is a step in the right direction,” he says.
Significant Improvement
Overall, by adding features and improving the machine learning model, the researchers improved the performance of the scoring system by 82%, as measured by the area under curve (AUC) plotting precision versus recall — also known as coverage versus efficiency. The model currently accounts for a 0.779 AUC, which is 82% better than the second EPSS version, which had a 0.429 AUC. An AUC of 1.0 would be a perfect prediction model.
Using the latest version of the EPSS, a company that wanted to catch more than 82% of exploited vulnerabilities would only have to mitigate about 7.3% of all vulnerabilities assigned a Common Vulnerabilities and Exposures (CVE) identifier, much less than the 58% of the CVEs that would have to be remediated using the CVSS.
The model is available through an API on the FIRST site, allowing companies to get the score of a particular vulnerability or to retrieve the highest scoring software flaws at any moment in time. Yet companies will need more information to determine the best priority for their remediation efforts, says Cyentia’s Jacobs.
“The data is free, so you can go get the EPSS scores, and you can go grab daily dumps of that, but the challenge is when you put it into practice,” he says. “Exploitability is only one factor of everything that you need to consider, and the other things, we can’t measure.”
Read More HERE